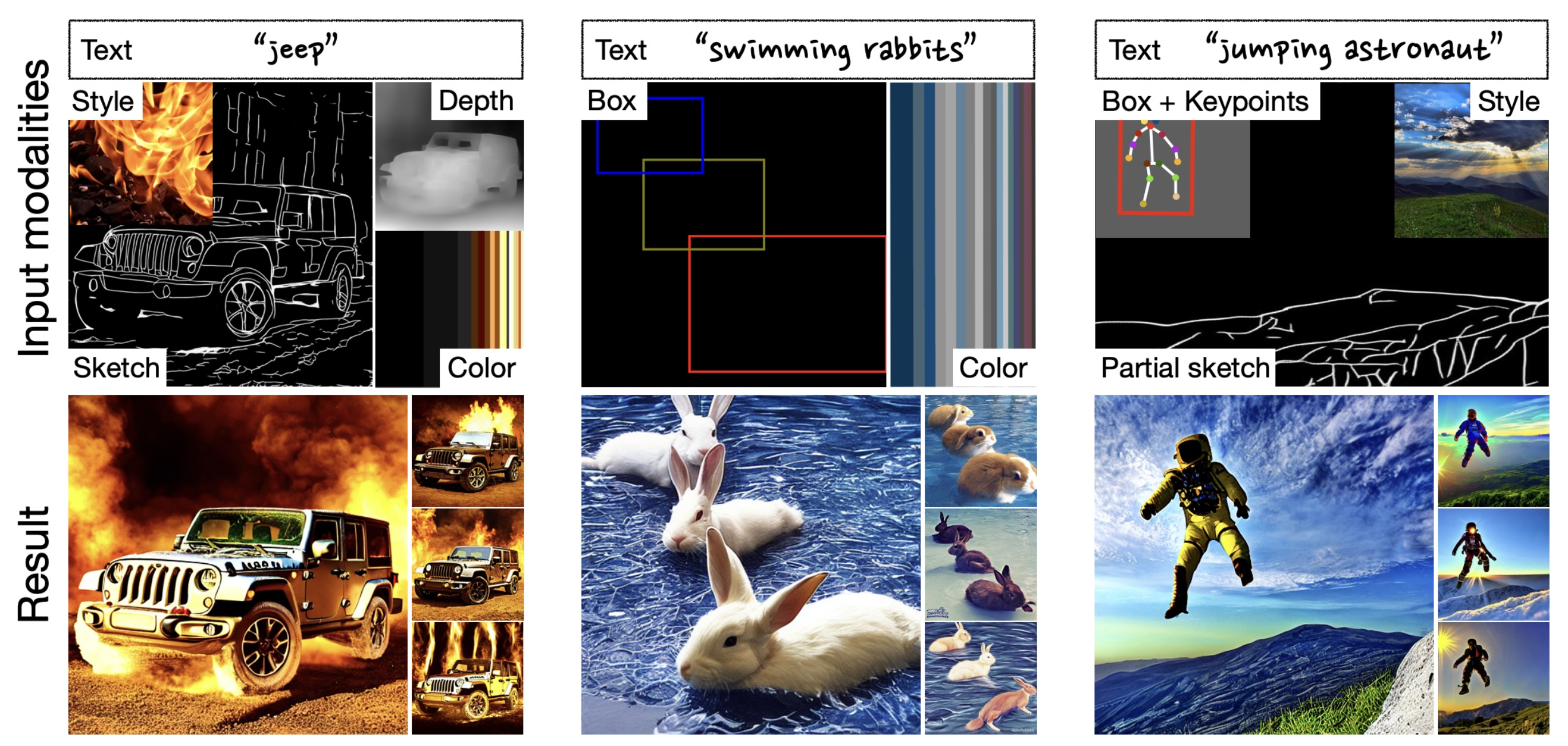
Figure 1. Generated images with multimodal conditions. By incorporating various types of input modalities (1st row), DiffBlender successfully synthesizes high-fidelity and diverse samples, aligned with user preferences (2nd row).
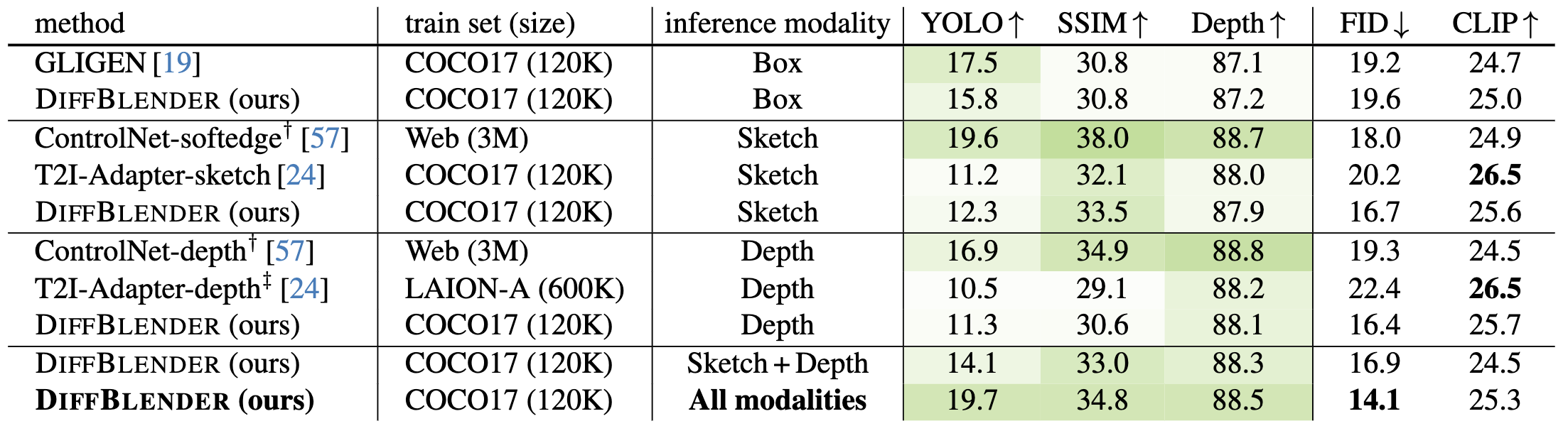
In this study, we aim to extend the capabilities of diffusion-based text-to-image (T2I) generation models by incorporating diverse modalities beyond textual description, such as sketch, box, color palette, and style embedding, within a single model. We thus design a multimodal T2I diffusion model, coined as DiffBlender, by separating the channels of conditions into three types, i.e., image forms, spatial tokens, and non-spatial tokens. The unique architecture of DiffBlender facilitates adding new input modalities, pioneering a scalable framework for conditional image generation. Notably, we achieve this without altering the parameters of the existing generative model, Stable Diffusion, only with updating partial components. Our study establishes new benchmarks in multimodal generation through quantitative and qualitative comparisons with existing conditional generation methods. We demonstrate that DiffBlender faithfully blends all the provided information and showcase its various applications in the detailed image synthesis.
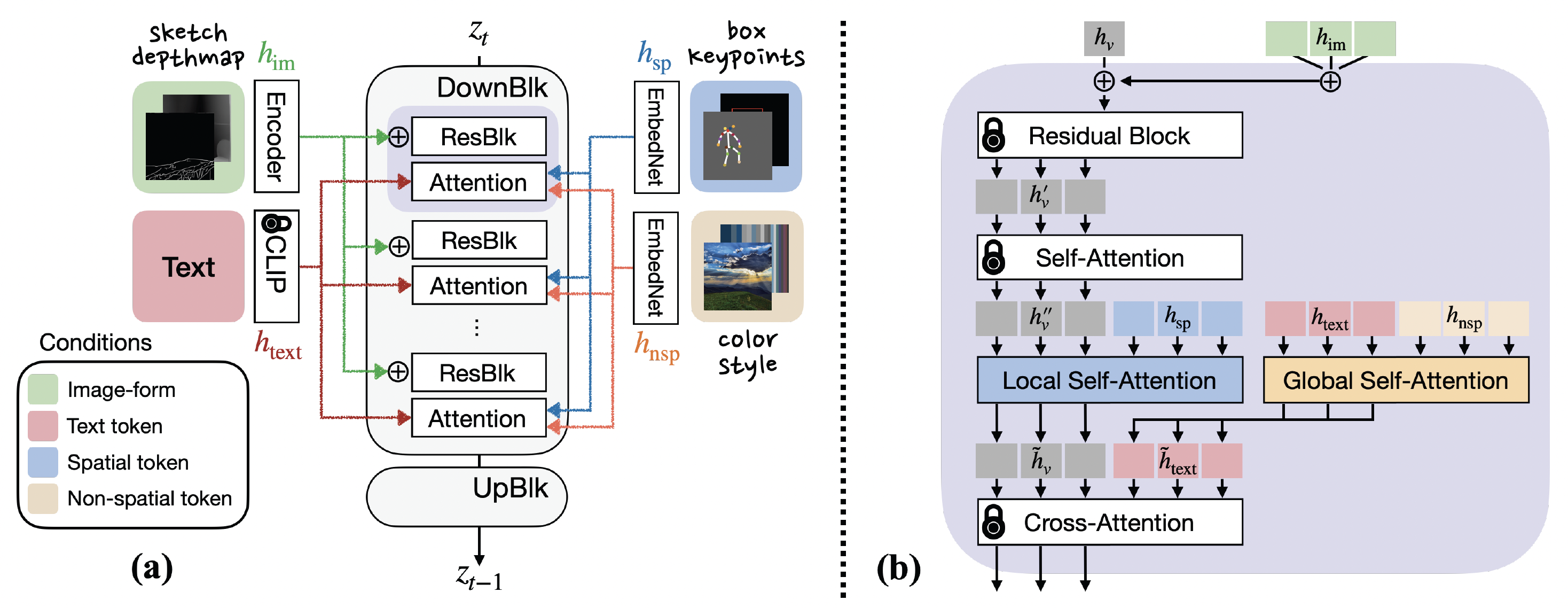
Figure 2. Overview of DiffBlender architecture. (a) illustrates the four types of conditions employed in DiffBlender and indicates where each part of information is used in the UNet layers. (b) focuses on the purple region in (a) to provide details of the DiffBlender's conditioning process. The lock-marked layers represent being fixed as the original parameters of SD. The remaining modules, small hypernetworks, denote the learnable parameters of DiffBlender.
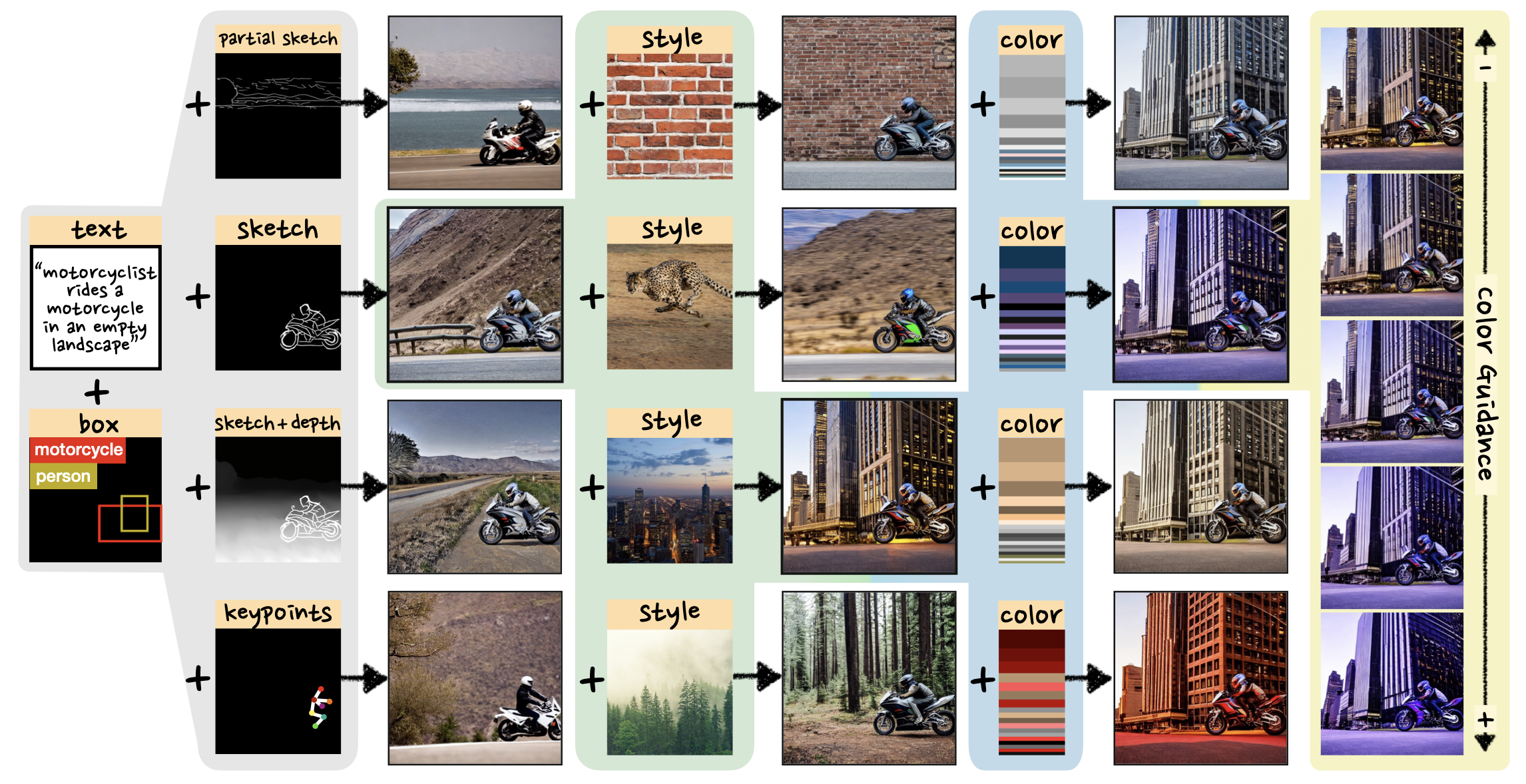
DiffBlender enables flexible manipulation of conditions, providing the customized generation aligned with user preferences. Note that all results are generated by our single model at once, not in sequence.

When a source image is provided, DiffBlender demonstrates the results preserving the structure inherent in that image, while effectively incorporating the style elements from a reference image.



DiffBlender has the capability to flexibly reconstruct a new scene by utilizing partial information from an input image. This enables us to customize scenes while retaining the contextual cues and layout from the original image.
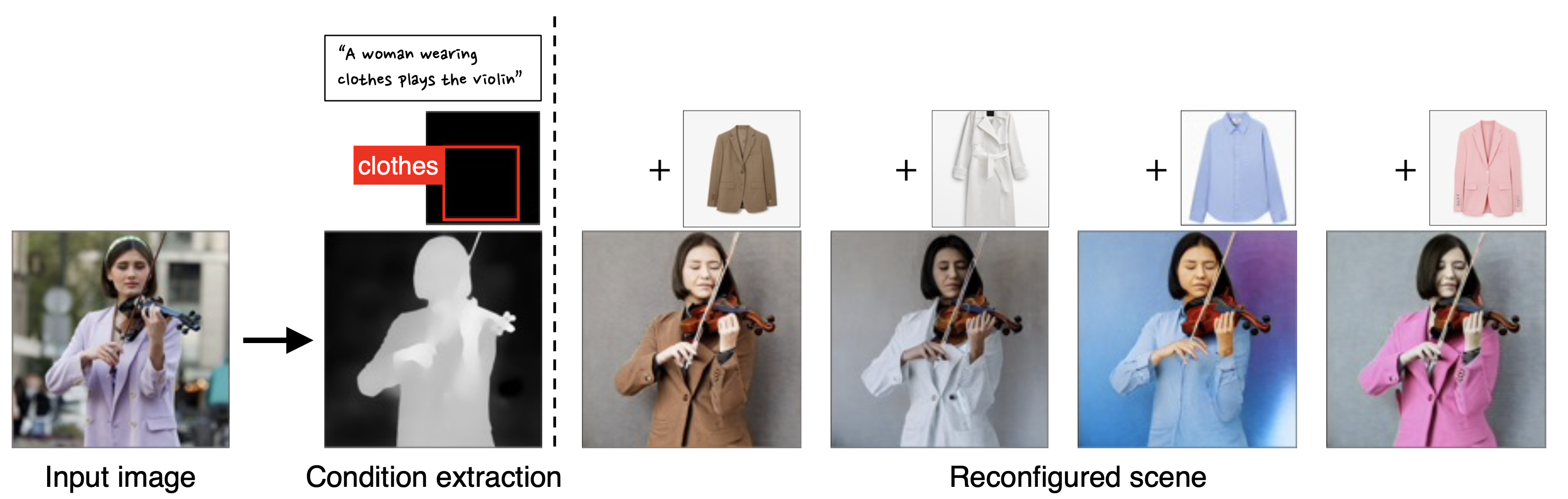
By altering the reference images associated with the clothing, it can reconfigure the scenes, modifying the outfit and style of the violinist.

Each row depicts the results of style and sketch guidance, respectively. We linearly manipulate the mode-specific guidance scale, where the center indicates scale=0 (original guidance).

Sketch guidances.

Depth guidances.

Color and style guidances.

Interpolating latents for the color palettes and reference image embeddings.
Interpolating latents for the color palettes.

Interpolating latents for the color palettes.

Interpolating latents for the reference image embeddings.
Interpolating latents for the reference image embeddings.

The box grounded with sun is shifted from the upper left to the upper right in a counter-clockwise direction. Throughout this shift, the partial sketch and reference image are consistently reflected, although there are slight variations in the terrain, brightness, or contrast, depending on the sun's position.

The astronaut's arms are gradually elevated, with the sketch and style being maintained.

@article{kim2023diffblender,
title={DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models},
author={Kim, Sungnyun and Lee, Junsoo and Hong, Kibeom and Kim, Daesik and Ahn, Namhyuk},
journal={arXiv preprint arXiv:2305.15194},
year={2023}
}